
[첫걸음] 데이터를 보는 눈, 파이썬으로 배우는 통계 기초
이 과정은 고용24에 먼저 신청 후, 내일배움카드로 결제해야 최종 신청이 완료됩니다.
훈련과정 탐색표 보기
권장 수강 대상
프로그래밍 입문자, 대학생, 현업 개발자
카테고리
🪙 국비지원
수강시간
11시간 51분
강의수
14개
강의 소개
커리큘럼

90% 국비지원으로 부담 없이 시작하세요!

🎁 수강하면 얻을 수 있는 것
• 강의 및 자료 평생 소장 - 완강 시 언제든 복습할 수 있어요. • 1:1 Q&A 지원 - 담당 멘토가 직접 답변해 드려요. • 수료증 발급 - 이력서, 포트폴리오에 활용할 수 있어요. • 실무 프로젝트 실습 - 업무, 일상에 빠르게 적용할 수 있어요.


데이터를 봐도 무엇을 알아야 할지 막막하셨나요? 📊
파이썬으로 기초 통계부터 전처리, 시각화, 모델링까지 데이터 분석의 전 과정을 차근차근 배워보세요.
타이타닉 생존자 예측, 캘리포니아 집값 분석 등 실제 데이터를 다루며,
"숫자 속 패턴이 보이기 시작하네!"라는 분석의 재미를 경험할 수 있습니다.
왜 지금, 이 과정이어야 할까요?
1️⃣ 통계로 시작하는 데이터 분석 입문
평균, 중앙값, 표준편차 등 기초 통계 개념을 실제 데이터에 적용하며 데이터를 해석하는 힘을 기릅니다.
2️⃣ 실제 데이터로 배우는 프로젝트 중심 학습
타이타닉 생존 데이터와 캘리포니아 집값 데이터를 활용해 전처리, 탐색, 시각화, 예측 모델링을 직접 실습합니다.
3️⃣ 분석부터 모델링까지 한 번에
데이터 종류 이해, 전처리, EDA, 회귀·분류 모델링, 성능 평가까지 데이터 분석의 전체 흐름을 경험할 수 있습니다.

어떤 강의를 들어야 할지 고민되시나요?
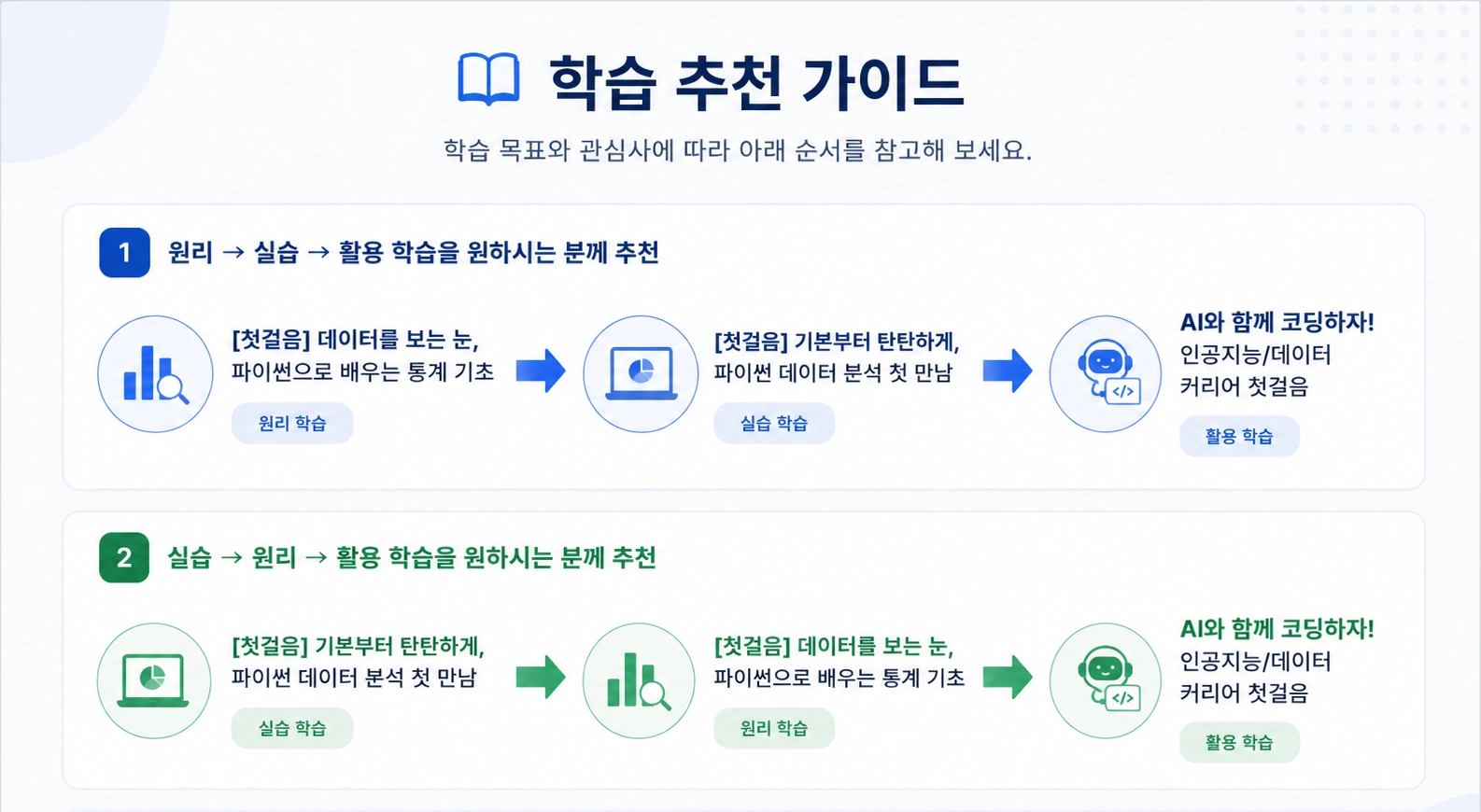
국비지원 데이터 분석 로드맵
TIP. 두 학습 방법 모두 최종 목표는 실무 역량 향상입니다. 자신의 학습 스타일에 맞게 선택해 보세요

이런 고민이 있나요?
통계를 배우지 못해 데이터 분석조차 엄두가 안 나요

통계를 배웠지만 실제 데이터에 어떻게 적용해야 할지 모르겠어요

지저분한 데이터를 보면 어디부터 손대야 할지 막막해요

시각화와 통계 해석으로 인사이트를 뽑아내고 싶어요


이렇게 성장할 수 있어요!
평균, 분산, 표준편차 등 핵심 통계 개념을 실제 데이터로 체득할 수 있어요

결측치, 이상치, 중복 처리 등 전처리 루틴을 익혀 깨끗한 데이터셋을 만들어요

통계 기반 EDA로 패턴, 관계, 가설을 발견하는 방법을 배워요

선형회귀, 로지스틱회귀를 적용해 기본 모델링 흐름을 이해할 수 있어요


프로젝트 맛보기

크리에이터

박형철
데이터를 '보는 눈'을 키우면 숫자는 스토리가 돼요. 통계와 파이썬으로 그 스토리를 함께 읽어봅시다!
• 현재 모두의연구소 데이터 사이언스 부트캠프 퍼실리테이터
• 연세대학교 수학과 석사
• 의료영상 EIT 논문, 대한응용수학회 포스터 발표 경험
• 신약개발 AI 및 비임상실험 기업 AI 솔루션 제공 사업 기획·연구
• 비전공자 대상 파이썬·머신러닝 실습 강의 다수 진행
커리큘럼
입문
11시간 51분